
Últimos Cambios
 Blog personal: El hilo del laberinto
Blog personal: El hilo del laberinto

|
|
|
Últimos Cambios |
|
Blog personal: El hilo del laberinto
|
|
|
Última Actualización: 24 de Julio de 2.000 - Lunes
Este documento describe el sistema de compresión utilizado entre los servidores de IRC-Hispano desde Mayo de 2.000. Esta propiedad del enlace se negocia de forma dinámica en cada enlace gracias a la infraestructura de negociación servidor <-> servidor descrita en otro documento.
Las librerías de compresión evaluadas durante el desarrollo de este proyecto proyecto fueron:
Ésta fue la elección final, por su popularidad, su consumo "ajustable" de CPU y, sobre todo, memoria, y por su facilidad para realizar compresión en modo "stream" y no en modo bloque.
Esta librería logra una compresión bastante mayor, pero a costa de un consumo de memoria y CPU exagerado, además de no permitir compresión en modo "stream".
Aunque el consumo de CPU y memoria es bastante bajo, su nivel de compresión es mediocre comparado con el de ZLIB.
Compresor todavía en una fase de desarrollo demasiado incipiente como para ser utilizado en una red en producción, aunque su nivel de compresión resulta destacable.
Dadas las características del protocolo IRC, sería perfectamente posible desarrollar un sistema de compresión personalizado y ajustado al mismo. No obstante ello podría suponer un constreñimiento al futuro desarrollo del protocolo, y no está claro que el nivel de compresión superase al de un compresor genérico por un margen lo bastante elevado como para justificar el coste. El consumo de CPU probablemente sí se vería beneficiado, pero en la actualidad cualquier CPU moderna es perfectamente capaz de saturar un enlace Internet mucho antes de saturar su CPU debido a la compresión, por lo que este factor tiene un peso relativamente bajo.
Por otra parte, no se descarta que el futuro se produzca una "hibridación" entre este esquema y ZLIB: en una primera etapa se comprime el comando utilizando un compresor específico, y su salida se optimiza todavía más mediante ZLIB.
Tal y como se explica en la página de negociación de enlaces, no es preciso realizar ninguna modificación en la configuración de los servidores para beneficiarse de la tecnología de compresión, ya que ésta estará típicamente activada por defecto.
Existen, no obstante, casos en los que interesa desactivar esta funcionalidad. El más evidente es cuando varios nodos están unidos a través de una red de alta velocidad (por ejemplo, una red local). En ese caso la compresión no mejora la ya de por sí rápida y holgada comunicación entre los nodos, y sólo consume CPU y memoria.
Como se explica en la página de negociación cada propiedad negociada se representa por una letra. En el caso de la compresión ZLIB (la actual), la letra asociada es ZETA ("z"). Su uso y configuración se detalla en la página indicada más arriba.
Una vez negociada compresión en un enlace, el sistema no admite deshabilitar dicha función mediante negociación. Es decir, una vez que se empieza a comprimir un enlace, no se puede dejar de comprimir.
Un IRCop puede verificar si un servidor soporta o no compresión, si un enlace está siendo comprimido y cuál es su nivel de compresión, utilizando el comando "stats l".
El comando "stats l" muestra ahora el nivel de compresión alcanzado en cada enlace del servidor, en ambos sentidos. Un nivel de compresión del 100% indica que no se está comprimiendo dicho enlace. Un nivel de compresión del 45%, por ejemplo, indica compresión 100:45.
Asimismo, los bytes enviados y recibidos son el tráfico comprimido. Es decir, si un enlace se está comprimiendo al 42%, y se indica que se han enviado 4561269 bytes, ese es el numero de bytes realmente enviado (comprimido); si no se emplease compresión, se hubieran enviado 10860164 bytes.
Como ya se ha explicado con anterioridad, cada línea a enviar se comprime y se transmite de forma inmediata. Ello provoca un consumo de CPU elevado, y un nivel de compresión inferior al deseable. Este enfoque se justifica porque:
Tras analizar el problema detenidamente se decidió implementar un esquema de microráfagas explícito, en las que el código del servidor IRC señala explícitamente dónde empieza y dónde acaba un bloque de comandos que podemos permitirnos comprimir como un único bloque, sin los problemas anteriores.
En el momento actual, las microráfagas implementadas se producen:
Las microráfagas pueden anidarse y, aunque deberían cerrarse adecuadamente, el servidor es capaz de recuperarse si una microráfaga no se completa como debe (aunque esta opción es peligrosa y no debe abusarse de ella).
El empleo de microráfagas mejora notablemente la compresión, y contribuye a aligerar de forma considerable la carga de CPU en situaciones de "join" o de enlaces muy cargados (ya que llegan varios comandos juntos en un unico datagrama, que serán procesados dentro de una microráfaga). El siguiente gráfico ilustra los beneficios de esta tecnología:
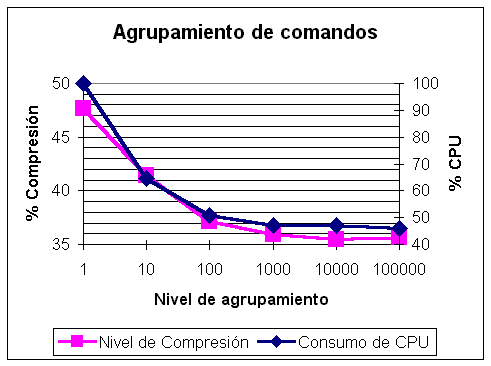
En este gráfico se observa que el uso de microráfagas mejora la compresión del 47% al 36%, y que el consumo de CPU se reduce a algo menos de la mitad. El nivel de agrupamiento que se indica en el gráfico es el número de comandos que comprimimos juntos, como un bloque.
Para hacer uso de las microráfagas (como ya se ha explicado, es posible anidarlas) hay que invocar a la función "inicia_microburst()" al principio del bloque, y llamar a "completa_microburst()" cuando hayamos terminado con ella. Cuando se cierren todas las microráfagas en curso (se pueden anidar), el servidor hará "flush" de todos los búferes de compresión y de todos los enlaces TCP/IP involucrados en las microráfagas, de forma automática. El servidor se hace cargo automáticamente de aquellos enlaces involucrados en microráfagas que se cierren antes de haberlas completado.
En esta sección se incluye parte del código fuente empleado para evaluar el sistema de compresión implementado:
Este programa toma su entrada estándar como fuente de datos y los comprime hasta alcanzar el final de la misma. Una vez completado, imprime en pantalla el nivel de compresión y el tiempo de CPU empleado. También imprime la ocupación de memoria.
Este programa permite experimentar con diferentes tamaños de bloque, simulando tamaños de microráfaga. El valor por defecto es uno, e implica microráfagas de un elemento; es decir, no microráfagas.
Se pueden variar algunos detalles del ejecutable (nivel de compresión, tipo de flush) para evaluar cambios en el nivel de compresión y de CPU.
#include <stdio.h>
#include <stdlib.h>
#include <zlib.h>
#include <unistd.h>
#include <sys/times.h>
#include <limits.h>
z_stream stream;
int total_memoria=0;
voidpf z_alloc(voidpf opaque, uInt items, uInt size) {
printf("Malloc: %d %d\n",items,size);
total_memoria+=items*size;
return calloc(items,size);
}
void z_free(voidpf opaque, voidpf address) {
printf("Free\n");
free(address);
}
int main(int argc, char *argv[]) {
char buf[16384],buf2[1638400];
int agrupamiento=0,AGRUPAMIENTO=1;
struct tms tms;
if(argc>1)
AGRUPAMIENTO=atoi(argv[1]);
printf("agrupamiento: %d\n",AGRUPAMIENTO);
stream.zalloc=z_alloc;
stream.zfree=z_free;
deflateInit(&stream,9);
while(gets(buf)!=NULL) {
stream.next_in=buf;
stream.avail_in=strlen(buf)+1;
stream.next_out=buf2;
stream.avail_out=1638400;
if(++agrupamiento<AGRUPAMIENTO) {
deflate(&stream,Z_NO_FLUSH);
} else {
deflate(&stream,Z_PARTIAL_FLUSH);
agrupamiento=0;
}
}
times(&tms);
printf("%d %d %d%%\n",stream.total_in,stream.total_out,
100*stream.total_out/stream.total_in);
printf("Memoria: %d\n",total_memoria);
printf("U: %f S: %f\n",(float)tms.tms_utime/CLK_TCK,(float)tms.tms_stime/CLK_TCK);
return 0;
}
Esta rutina es similar a la anterior, pero para el caso BZIP2.
#include <stdio.h>
#include <stdlib.h>
#include <bzlib.h>
#include <unistd.h>
bz_stream stream;
int total_memoria=0;
void * bz_alloc(void *opaque, int items, int size) {
printf("Malloc: %d %d\n",items,size);
total_memoria+=items*size;
return calloc(items,size);
}
void bz_free(void *opaque, void *address) {
printf("Free\n");
free(address);
}
int main(void) {
char buf[16384],buf2[16384];
stream.bzalloc=bz_alloc;
stream.bzfree=bz_free;
BZ2_bzCompressInit(&stream,9,0,9);
while(gets(buf)!=NULL) {
stream.next_in=buf;
stream.avail_in=strlen(buf)+1;
stream.next_out=buf2;
stream.avail_out=16384;
BZ2_bzCompress(&stream,BZ_FLUSH);
}
printf("%d %d %d%%\n",stream.total_in_lo32,stream.total_out_lo32,
100*stream.total_out_lo32/stream.total_in_lo32);
printf("Memoria: %d\n",total_memoria);
return 0;
}
#include <stdio.h>
#include <stdlib.h>
#include <zlib.h>
#include <unistd.h>
#include <sys/times.h>
#include <limits.h>
z_stream stream;
int total_memoria=0;
voidpf z_alloc(voidpf opaque, uInt items, uInt size) {
printf("Malloc: %d %d\n",items,size);
total_memoria+=items*size;
return calloc(items,size);
}
void z_free(voidpf opaque, voidpf address) {
printf("Free\n");
free(address);
}
int main(int argc, char *argv[]) {
char buf[1638400],buf2[1638400];
int agrupamiento=0,AGRUPAMIENTO=1;
struct tms tms;
char *p;
if(argc>1)
AGRUPAMIENTO=atoi(argv[1]);
printf("agrupamiento: %d\n",AGRUPAMIENTO);
stream.zalloc=z_alloc;
stream.zfree=z_free;
deflateInit(&stream,9);
p=buf;
while(gets(p)!=NULL) {
p+=strlen(p)+1;
if(++agrupamiento>=AGRUPAMIENTO) {
stream.next_in=buf;
stream.avail_in=p-buf;
stream.next_out=buf2;
stream.avail_out=1638400;
deflate(&stream,Z_PARTIAL_FLUSH);
agrupamiento=0;
p=buf;
}
}
if(p!=buf) {
stream.next_in=buf;
stream.avail_in=p-buf;
stream.next_out=buf2;
stream.avail_out=1638400;
deflate(&stream,Z_PARTIAL_FLUSH);
}
times(&tms);
printf("%d %d %d%%\n",stream.total_in,stream.total_out,
100*stream.total_out/stream.total_in);
printf("Memoria: %d\n",total_memoria);
printf("U: %f S: %f\n",(float)tms.tms_utime/CLK_TCK,(float)tms.tms_stime/CLK_TCK);
return 0;
}
Esta rutina descomprime la salida de un servidor empleando compresión, para validar su correcto funcionamiento, especialmente en el aspecto de microráfagas.
#include <stdio.h>
#include <stdlib.h>
#include <zlib.h>
#include <unistd.h>
#include <sys/times.h>
#include <limits.h>
#include <sys/uio.h>
z_stream stream;
int main(void) {
char buf[1638400],buf2[1638400];
struct tms tms;
int count;
stream.zalloc=NULL;
stream.zfree=NULL;
inflateInit(&stream);
while((count=read(0,buf,1024))) {
stream.next_in=buf;
if(!stream.total_in) {
stream.next_in+=0321;
count-=0321;
}
stream.avail_in=count;
stream.next_out=buf2;
stream.avail_out=1638400;
inflate(&stream,Z_SYNC_FLUSH);
count=1638400-stream.avail_out;
buf2[count]='\0';
if(count) printf("%s",buf2);
}
times(&tms);
printf("%d %d %d%%\n",stream.total_in,stream.total_out,
100*stream.total_out/stream.total_in);
printf("U: %f S: %f\n",(float)tms.tms_utime/CLK_TCK,(float)tms.tms_stime/CLK_TCK);
return 0;
}







Más información sobre los OpenBadges
Donación BitCoin: 19niBN42ac2pqDQFx6GJZxry2JQSFvwAfS

